

AI, or artificial intelligence, is a broad field that encompasses various approaches and techniques aimed at enabling computers or machines to perform tasks that typically require human intelligence. While there are different branches and methods within AI, the general workings involve the following steps:
Data Collection: AI systems rely on large amounts of data to learn and make informed decisions. This data can be structured or unstructured, and it should be representative of the task or problem the AI system aims to solve. Data Preprocessing: Before training an AI model, the collected data needs to be preprocessed. This involves cleaning the data, handling missing values, normalizing or scaling features, and converting data into a suitable format for analysis. Model Training: AI models, such as neural networks, are trained using the preprocessed data. During training, the model learns the underlying patterns, relationships, and representations present in the data by adjusting its internal parameters. This is typically done through optimization algorithms, like gradient descent, which minimize the difference between the model's predictions and the ground truth values in the training data.
Evaluation and Validation: Once the model is trained, it is evaluated using separate validation data to assess its performance. Various metrics are used to measure how well the model generalizes to unseen data and whether it achieves the desired accuracy or objective.
Deployment and Inference: After the model has been trained and evaluated, it can be deployed in a production environment to make predictions or decisions. New, unseen data is fed into the model, and it uses the learned patterns and representations to generate predictions, classify objects, make recommendations, or perform other tasks based on its specific application.
Feedback and Iteration: AI systems can be improved through a feedback loop. The model's performance and outputs are continuously monitored, and new data can be collected to retrain and update the model periodically. This iterative process helps enhance the AI system's performance and adapt to changing conditions. It's important to note that the specific algorithms, techniques, and approaches used in AI can vary depending on the problem domain and the desired outcome. Machine learning, deep learning, natural language processing, and other subfields of AI offer different tools and methods to tackle various challenges. Additionally, AI systems can be supervised (with labeled data), unsupervised (without labeled data), or semi-supervised (a combination of both). Reinforcement learning is another branch of AI where agents learn through interactions with an environment to maximize rewards.
Overall, AI systems leverage data, algorithms, and computational power to mimic or augment human intelligence and automate tasks that were traditionally performed by humans.
AI generated ContentImage generation using AI involves utilizing algorithms and models to create new images based on certain principles, keyword associations, sorting techniques, and the addition of noise. The process typically involves a generative model, such as a Variational Autoencoder (VAE) or a Generative Adversarial Network (GAN), to generate realistic and coherent images.
The first step in image generation is to define the principles or guidelines for the desired images. These principles can include stylistic choices, visual characteristics, or thematic elements that the generated images should adhere to. For example, if the desired theme is "nature," the principles could include landscapes, animals, and vibrant colors.
Keywords play a crucial role in generating specific images. By providing relevant keywords, you can guide the AI model to focus on specific objects, scenes, or concepts when generating the images. These keywords act as prompts to direct the model's attention and generate images aligned with the given keywords. For instance, if the keywords are "beach," "sunset," and "palm trees," the model will prioritize generating images that reflect those elements.
Sorting photos can be done based on various criteria such as image quality, relevance to the given keywords, or visual similarity. Sorting helps to filter out unwanted images and select the most suitable ones for generating new images. This step ensures that the generated images are consistent with the desired style or theme.
Noise is often introduced during the image generation process to add diversity and prevent overfitting. Random noise can be injected into the generative model to create variations within the generated images. (Seed) By doing so, the model can produce a range of different images while still adhering to the specified principles and keywords.
To generate images, a seed is typically used as the starting point for the generative model. The seed can be a random vector or a predetermined input that serves as the initial condition for generating the image. By altering the seed, you can generate different images while maintaining the same principles and keywords. This allows for exploration and discovery of various visual possibilities within the defined parameters.
Overall, image generation per AI involves leveraging principles, keyword associations, sorting techniques, and the incorporation of noise to guide the generative model in producing coherent and novel images based on predefined criteria.
AI generated ContentThe sampler is responsible for generating new images by sampling from the learned distribution of the generative model. It takes the latent space representation, typically a random vector or seed, as input and produces an image as output. By sampling from the model's latent space, the sampler generates diverse images that exhibit the desired characteristics or follow the specified principles.
The latent space can be thought of as a high-dimensional space in which the generative model has learned to represent different variations and features of the training data. By exploring different points or regions within this latent space, the sampler can produce a wide range of unique images while maintaining coherence and adherence to the specified principles.
In summary, the sampler plays a crucial role in image generation by sampling from the generative model's latent space and producing new images based on the input seed or random vector. It allows for the creation of diverse and novel images that align with the desired criteria.
AI generated ContentMy primary goal was to generate captivating patterns using hexagons. To begin my exploration, I turned to a mobile app called Artist.ai, which I accessed through a weekly subscription. However, my curiosity extended beyond this specific app, as I eagerly experimented with various AI image generation apps available on the App Store. One of my personal favorites was VideoLeap, an iOS app renowned for its video editing capabilities, which also integrated an exciting AI feature for image creation based on text prompts.
For my hexagonal pattern generation, I provided a prompt along the lines of "Generate a hexagonal pattern." I discovered that many of these apps leveraged the power of two remarkable open-source trained AI models: OpenJourney and stabelDiffusion. These models, created by a collaborative community, offered remarkable image generation capabilities. Harnessing the potential of these trained AI models enabled me to delve into the world of hexagonal patterns, pushing the boundaries of my creative endeavors with the aid of cutting-edge technology.

... or even more complex addvices like: Pattern geometric black white stickly connected few lines plain seamless loop tile objects hexagon high contrast
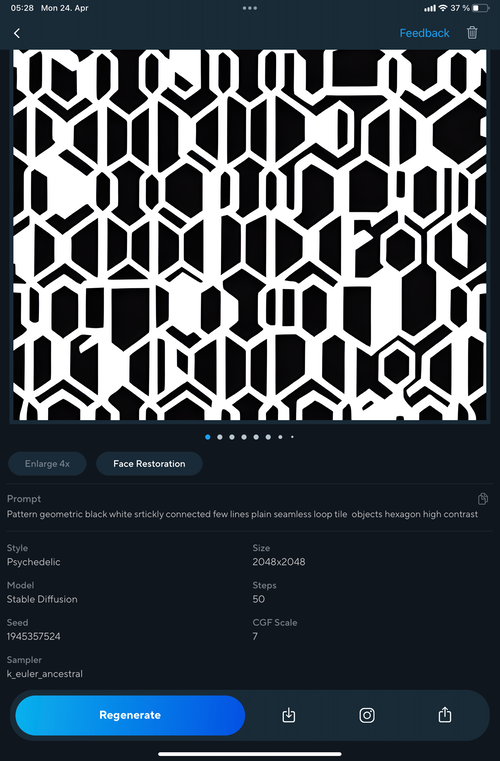
Then I set a reference image, and the results became even more intriguing. Artist.ai offers a wide range of trained models, including categories such as cyberpunk, painting, Picasso, anime, and more. One of the main takeaways from this experiment is that image generation AI has a strong focus on Avatars. It allows for the creation of new, younger, more beautiful, or even cyberpunk-inspired images that incorporate the user's own face. This functionality is particularly useful in mobile apps.
To enhance the generative process, I introduced hexagons into the mix and added the prompt: "Black and white abstract." The choice of colors in the resulting image is determined by the specific style selected during the generation process. This combination of prompts and styles adds depth and diversity to the generated images, resulting in a captivating visual experience.





Picasso Style:

Most of the trained models in leapAI are developed using stock image databases that match keywords with photos of objects. The models then analyze the given prompt and combine various photos to create a composition that fits the desired outcome, taking into account the noise present in the images. Each model is associated with a specific Seed, which represents the basic value for generating the noise. Using the same seed will produce the same image.
During my search for a platform to train models for my own graphics, I came across leapAI. It offered the opportunity to create a model that could mimic my unique graphic style, specifically tailored to a certain painting series I had in mind.
With leapAI, I was able to train my own models for a nominal fee of $2. All I needed to do was provide a prompt in the format of @your_model_name. I had the flexibility to upload as many pictures as I wanted, and the training process typically took around 10-30 minutes. Throughout the semester, I trained a total of 19 models and generated approximately 3000 images, all of which are stored on the leapAI platform. While most of the models were designed to generate images of humans or animals, there were a handful of presets available, such as girl, businessman, or dog. I specifically chose styles that aligned with my artistic vision.
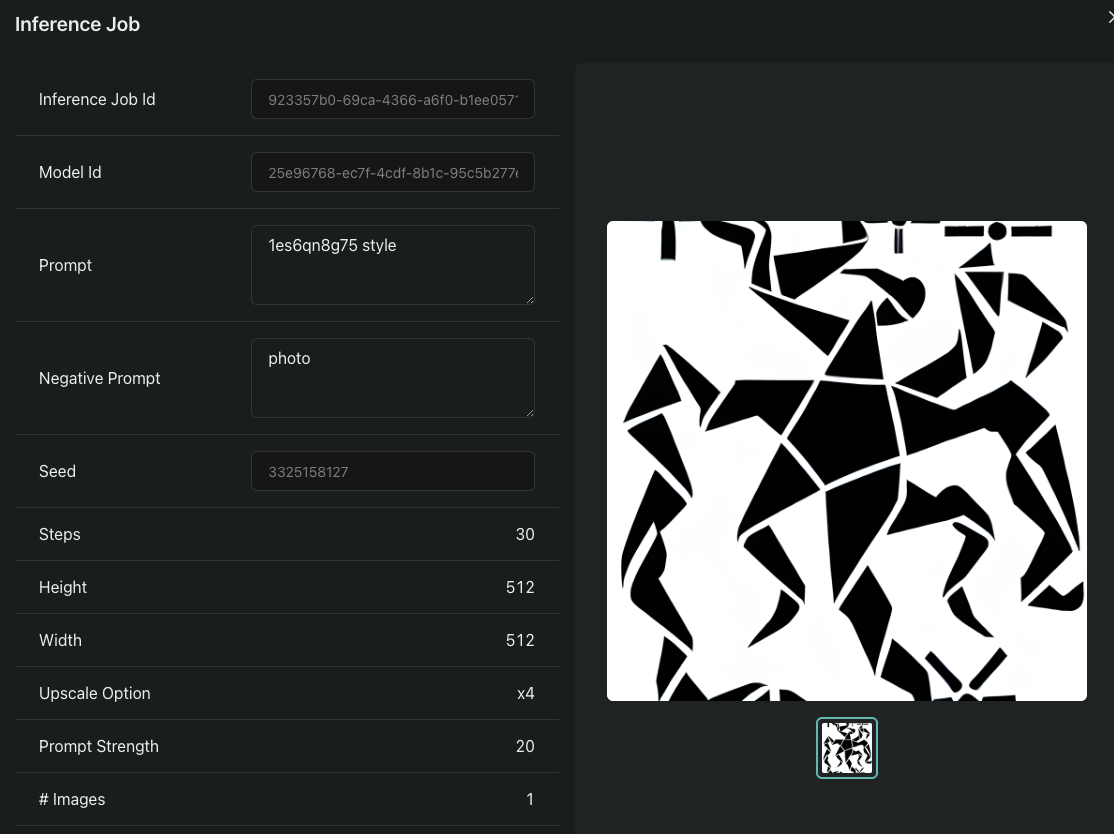 Here you see exactly everyting what data the imge gets.
Here you see exactly everyting what data the imge gets.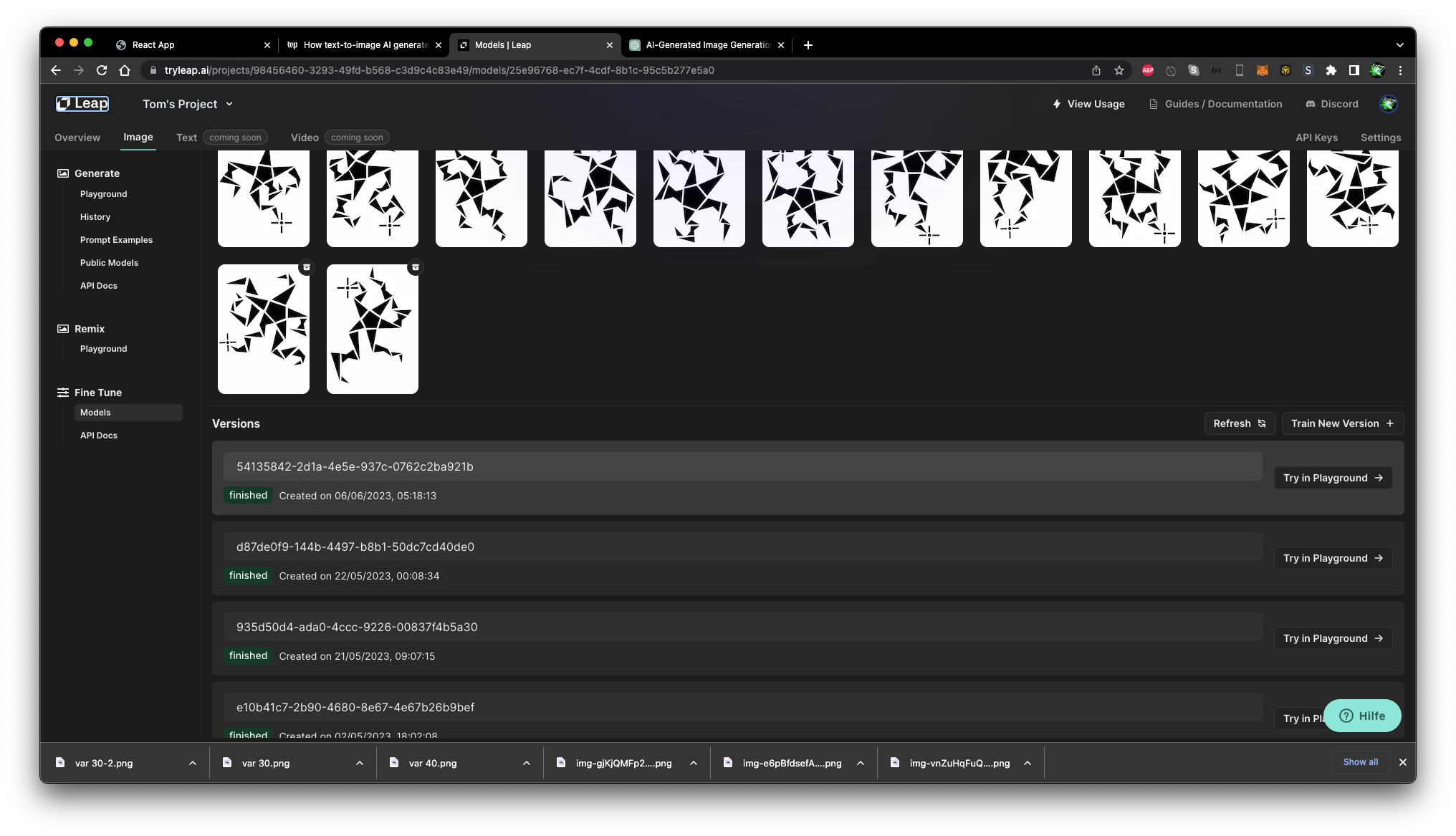 Here are the Modeltraingview with the sample and the varaitions
Here are the Modeltraingview with the sample and the varaitions
 8 training samples output
8 training samples output  12 training samples output
12 training samples output 22 training samples output
22 training samples output
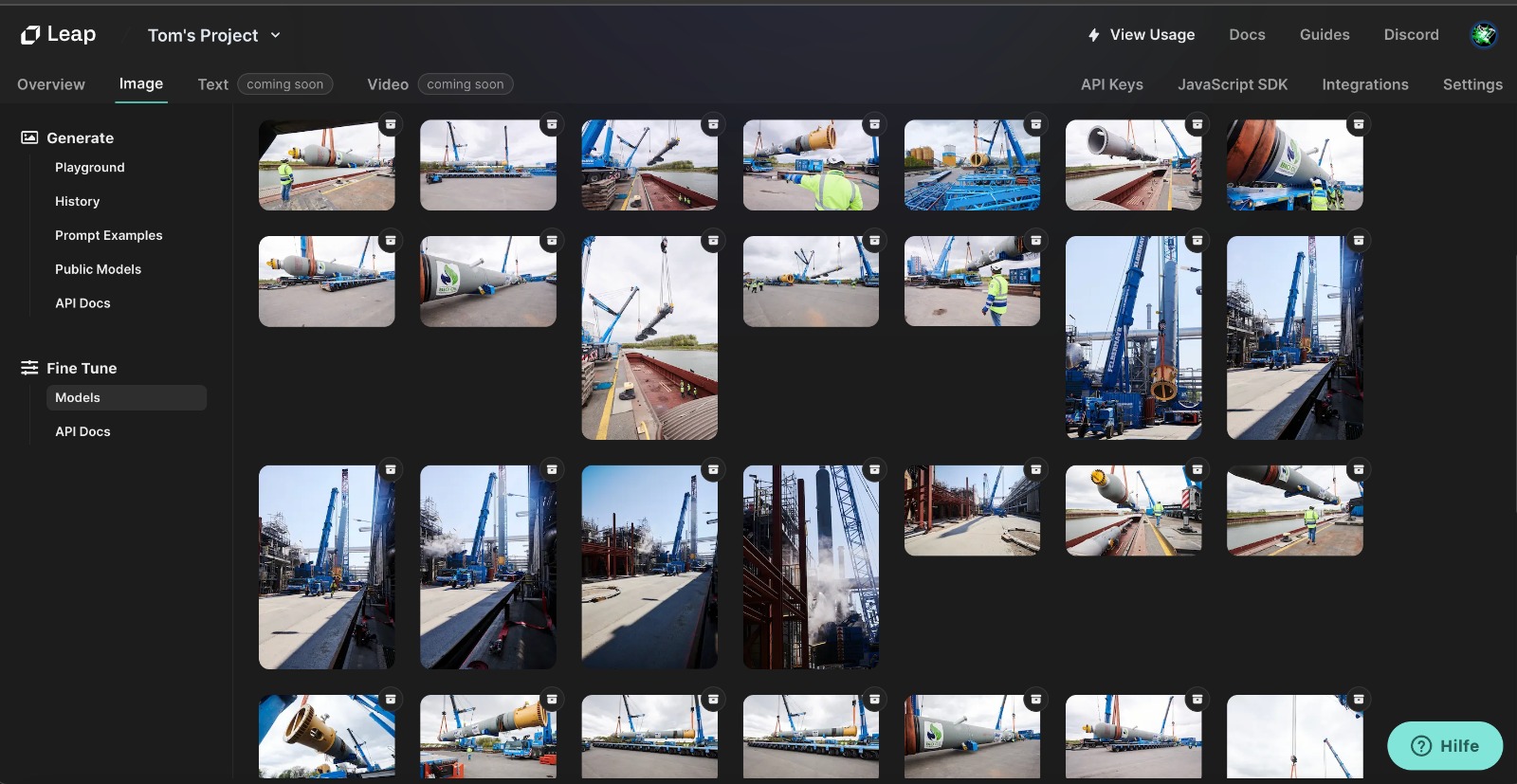
A professional photographer graciously provided me with a collection of his remarkable photos, captured during his work on a significant project for OMV. These photos contain sensitive and confidential information related to OMV's operations; however, I have been granted permission to showcase them in a university context. It's an intriguing use case, as OMV has strict regulations against revealing their actual facilities due to proprietary reasons. To explore alternative options, we decided to utilize these images to train an AI model.
By feeding the model approximately 30-40 images of the docks, we witnessed the remarkable capabilities of the AI in generating imaginative pipelines and construction buildings. This transformative process allowed us to visualize and conceptualize potential structures without compromising OMV's confidential information. It was a fascinating exploration of how AI can contribute to the creative and problem-solving aspects of industries while upholding the necessary confidentiality and security measures.








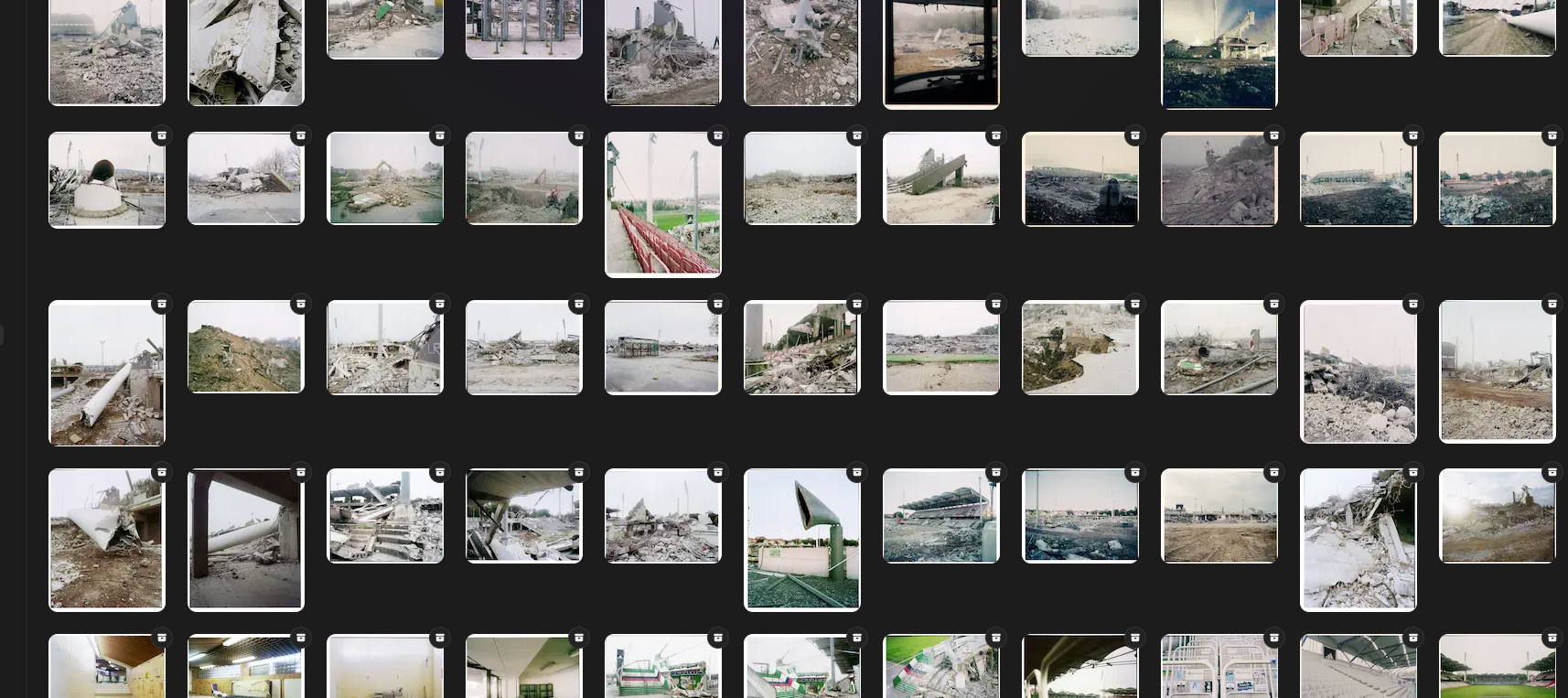
The photographer, whom I had initially approached, kindly provided me with a series of images showcasing the torn-down Hanappi station. These photos were subsequently compiled into a captivating book. Intrigued by the AI's ability to handle abstract or distorted images, I embarked on an exploration of its capabilities.
What fascinated me the most was the AI's remarkable capacity to analyze and interpret the photographs. When presented with these images, the AI seemed to embark on a journey of restoration and reconstruction, attempting to piece together the fragmented elements and restore a sense of coherence. Witnessing the AI's interpretation of the abstract and disrupted images was a captivating experience, shedding light on its potential to breathe new life into seemingly fragmented compositions.
This encounter with the AI's response to abstract and disturbed images opened up new avenues of artistic exploration and highlighted the machine's ability to perceive and reinterpret visual information. It showcased the transformative power of AI in uncovering hidden narratives and reconstructing visual representations, adding a unique and thought-provoking dimension to the artistic process.






Here is where my journey began: I specialize in designing graphical and abstract real paintings using various materials. I've named this project "ISeeMyselfFellThinking." The graphical shapes I create have significant meaning. Let me explain:
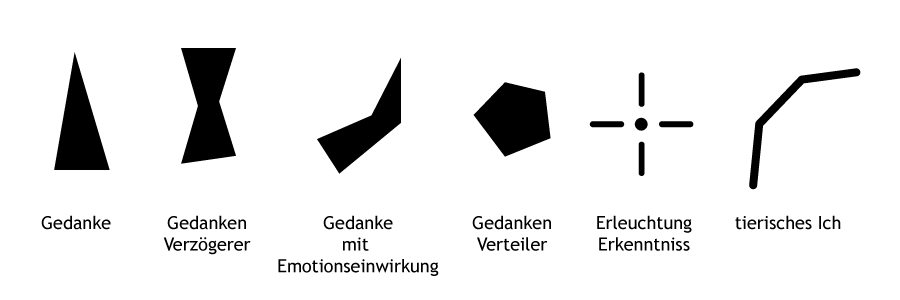
The patterns and new shapes I design represent "Thoughts." These shapes don't have specific meanings; rather, they aim to capture the complexity of decision-making and taking the right actions. Each thought has a starting point, and numerous paths are explored to reach a final solution. Inspired by this concept, I convert these abstract shapes into vector graphics. I utilize them to train a model that can generate Thoughts autonomously. For the final training, I created 52 different samples. Initially, I exported eight vector graphics as PNG files and used them in the training process.
Unfortunately, the outputs were not satisfying. They didn't reflect my graphic style nor the essence of a Thought. The generated images were overly abstract and lacked the precision associated with the works of Tom Peak. To improve the results, I realized that I needed to train the model with more diverse datasets. Additionally, I incorporated prompt guidance during the generation process, using the raw data as a foundation.
Man in Tom Peak style

Fox head in Tom Peak style … I felt in love with the fox head and sticked to it as a reference. I was not shure if most of them just variation of the logo of the firefox browser.
 …lots of missmatches
…lots of missmatches
It doesn't work as intended. There should be a simpler or more streamlined method for referencing a style during training to generate via prompts and style. As a solution, I created an animated SVG, which can be found online at www.tompeak.com/waxhex.
 first learning
first learningThese creations are essentially hexagons, but they intentionally break away from symmetry. To train my artistic model, I captured screenshots and fed them into the training process. The outcome was a resounding success.
The model absorbed the unique characteristics of these non-symmetric hexagons and incorporated them into its generative capabilities. It was fascinating to witness how my artistic vision came to life through the model's output. Each screenshot played a crucial role, allowing the model to understand my style and produce mesmerizing visual compositions that celebrated the beauty of imperfection.
This achievement has fueled my passion for pushing artistic boundaries. As I continue to refine my techniques and explore new artistic possibilities, I am eager to discover the intersection of art and technology, inspiring new realms of creative expression.

The maschine want to make heads. So i filled something about a face of a for in it. The results where great.











My style is, to make thoughts visual in an abstract way. Thats the system:
I haven't given up on my fundamental idea of having an AI generate Tom Peaks 2023. I utilized the leapAI API on a webpage (ai.tompeak.com), although they recently made some changes to the API, rendering it non-functional at the moment. However, using the API would provide an output, and by making a 2€ PayPal donation, you would receive the high-resolution image with a Tom Peak watermark (signature) sent via email. Additionally, I possess an online proof certificate. Every IP address can generate an image every 30 minutes, with each image generation costing me 0.005$.
UPDATE: LeapAI shut down this service:









































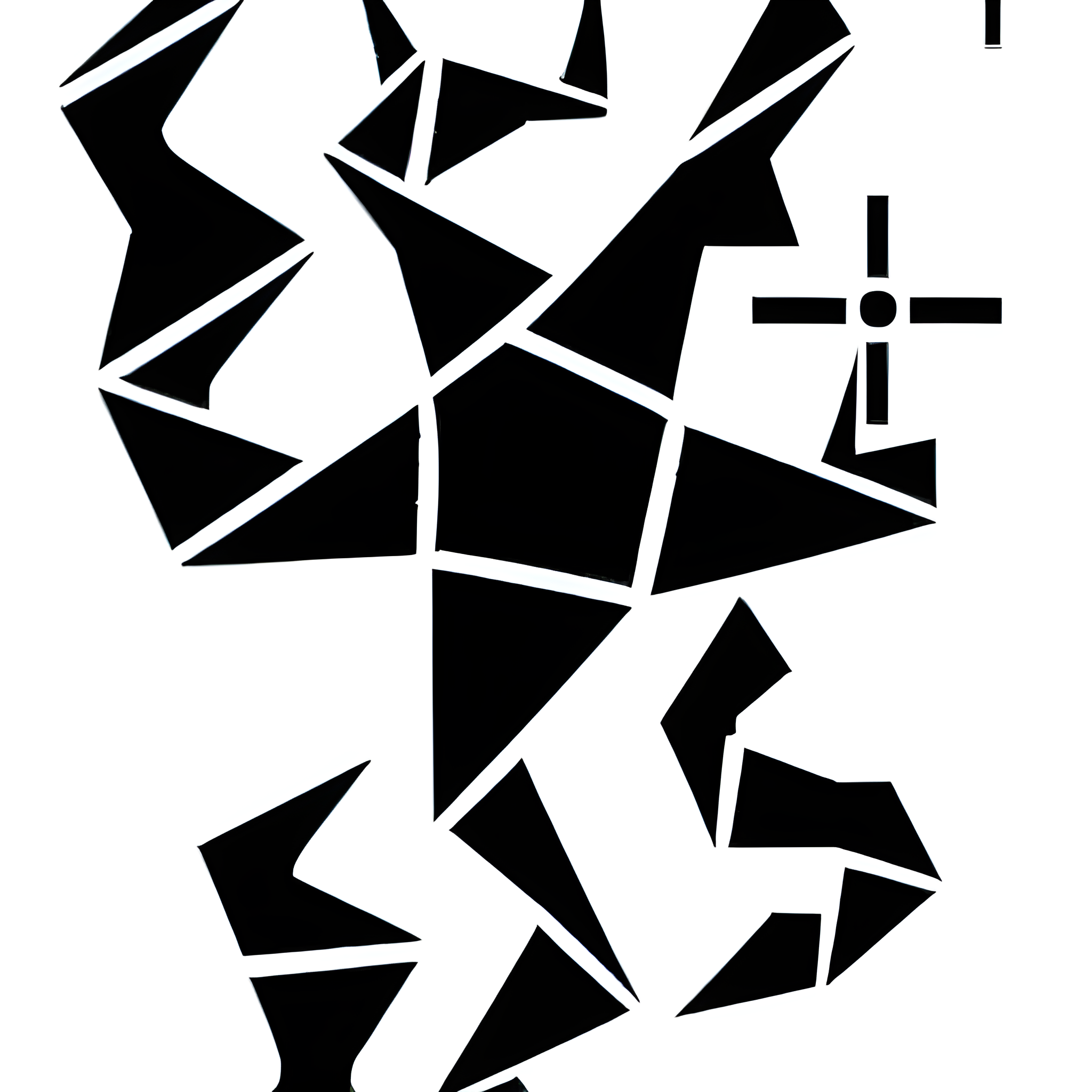







































































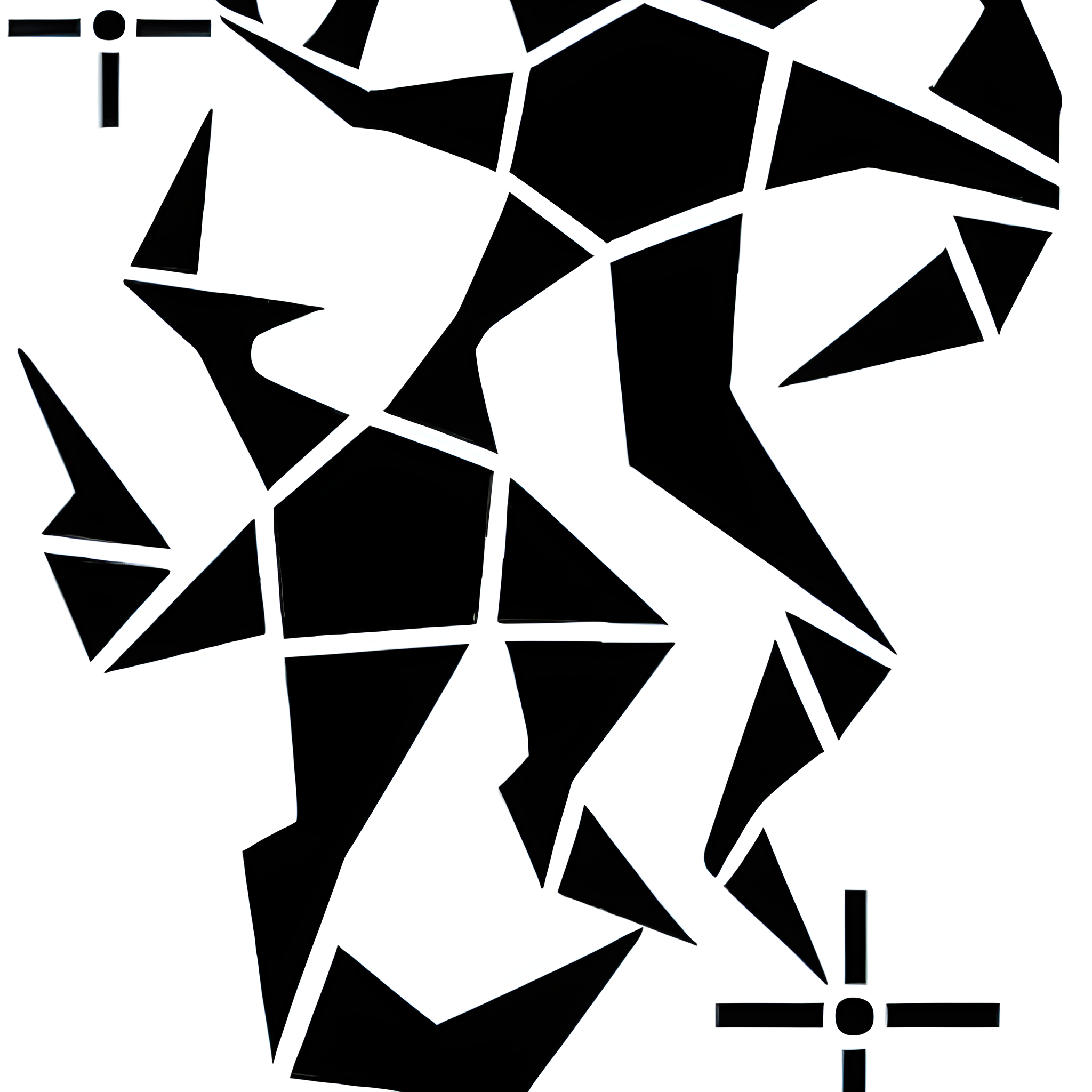




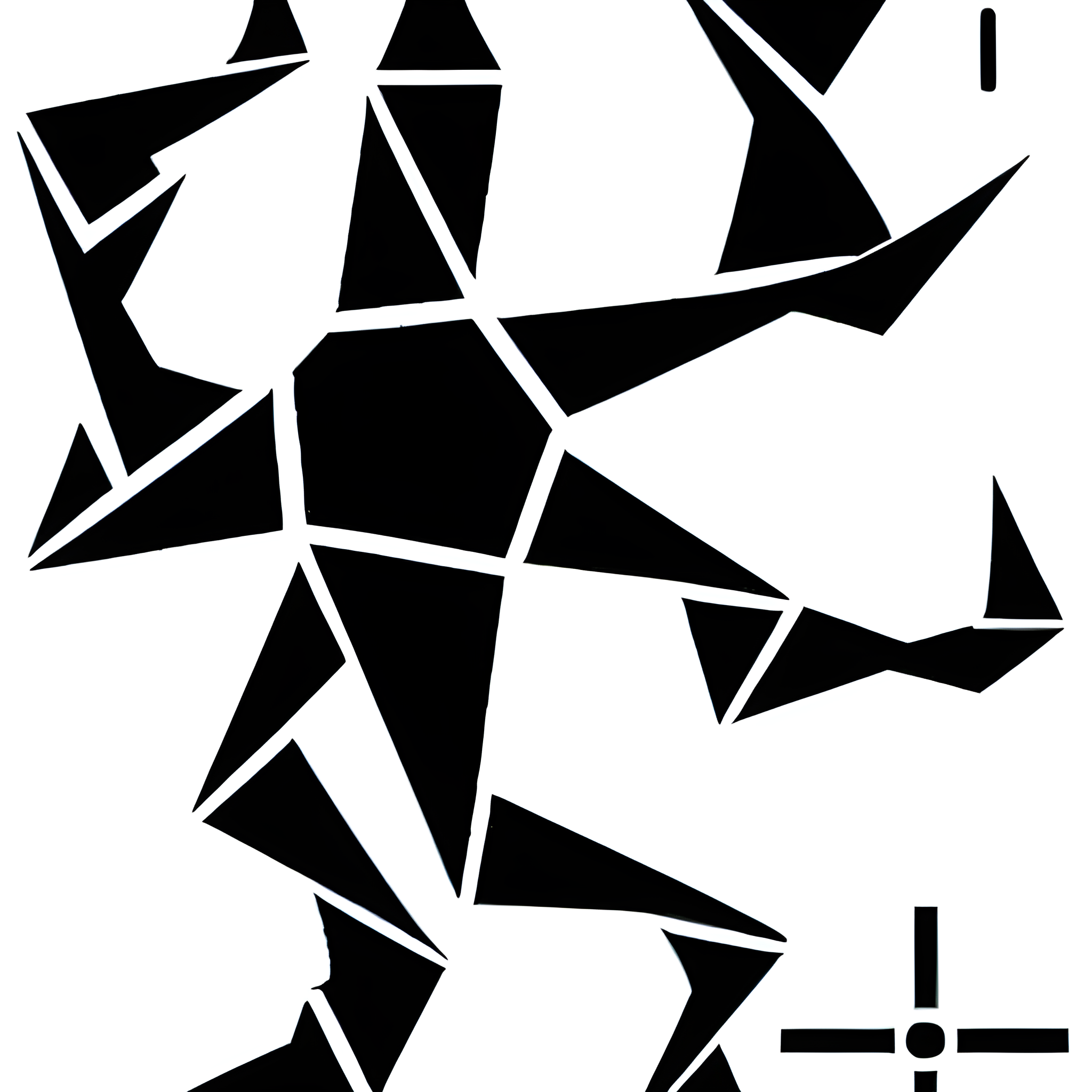















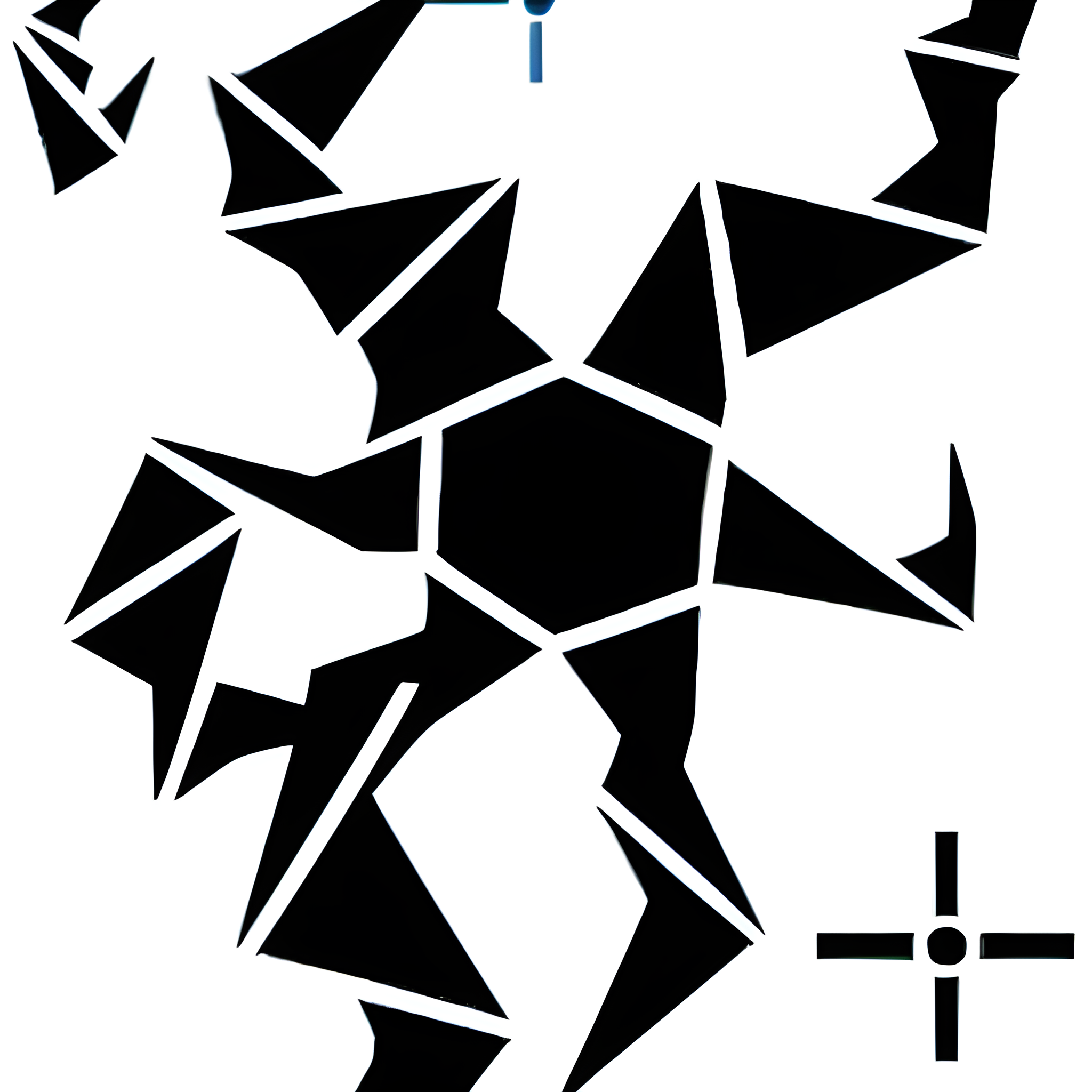








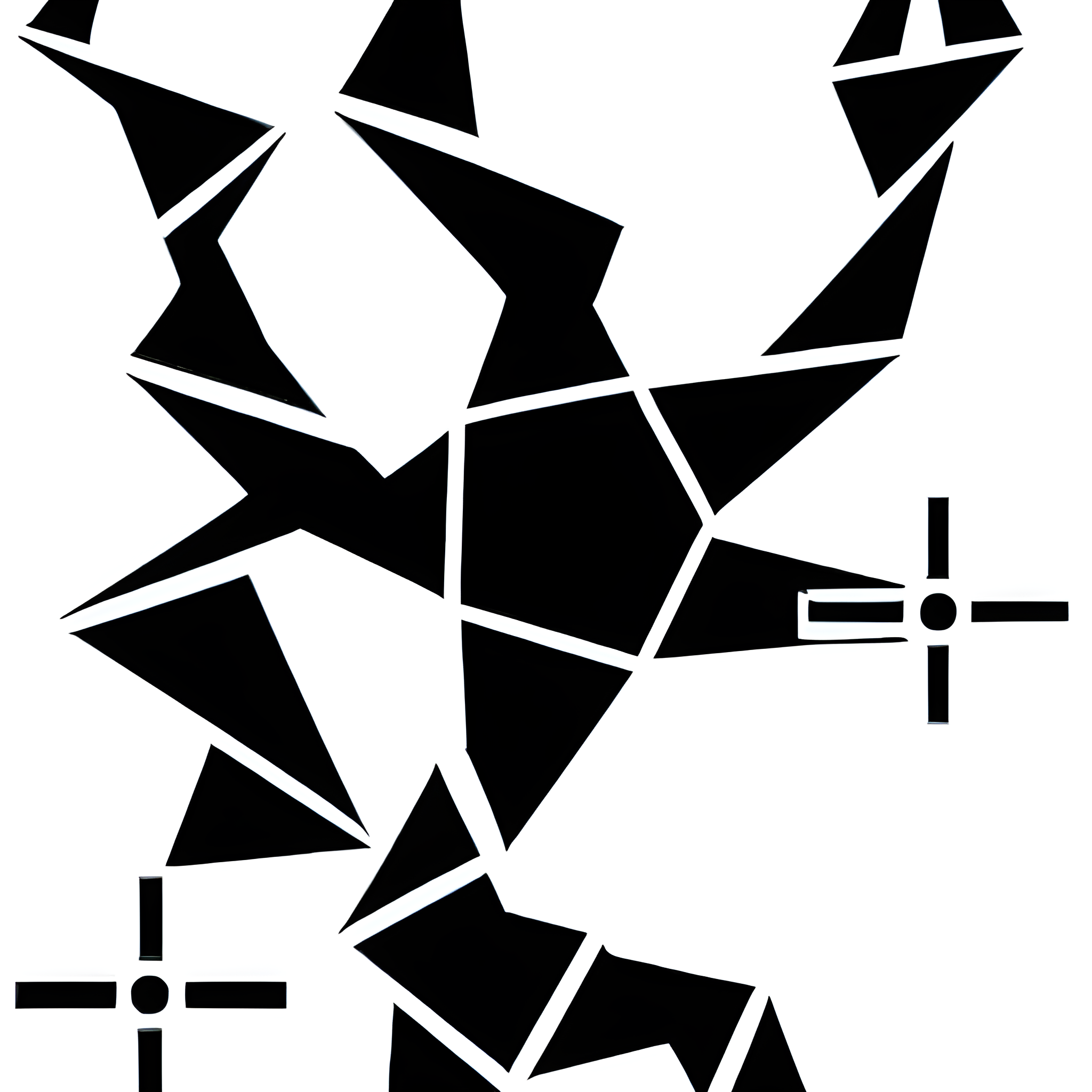







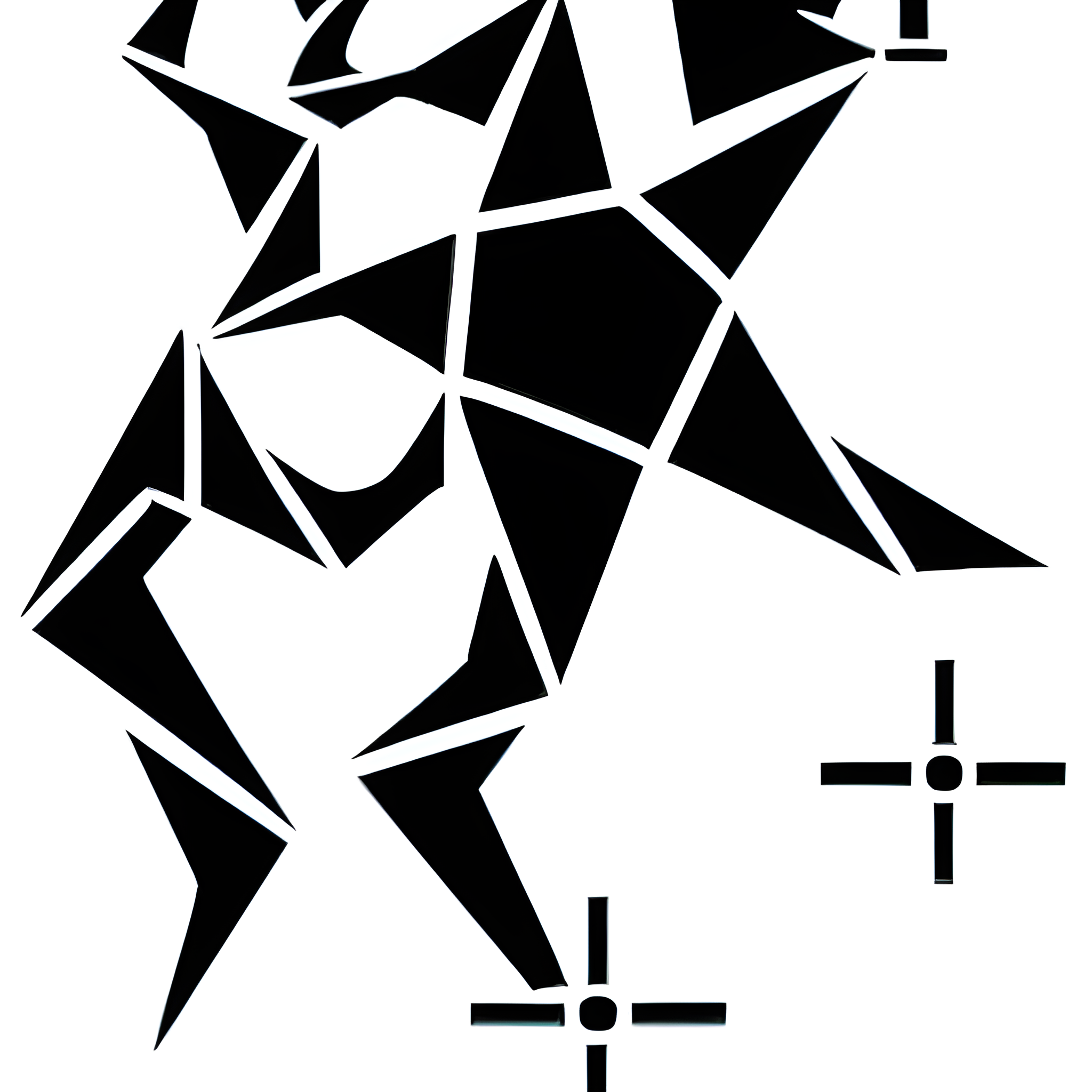
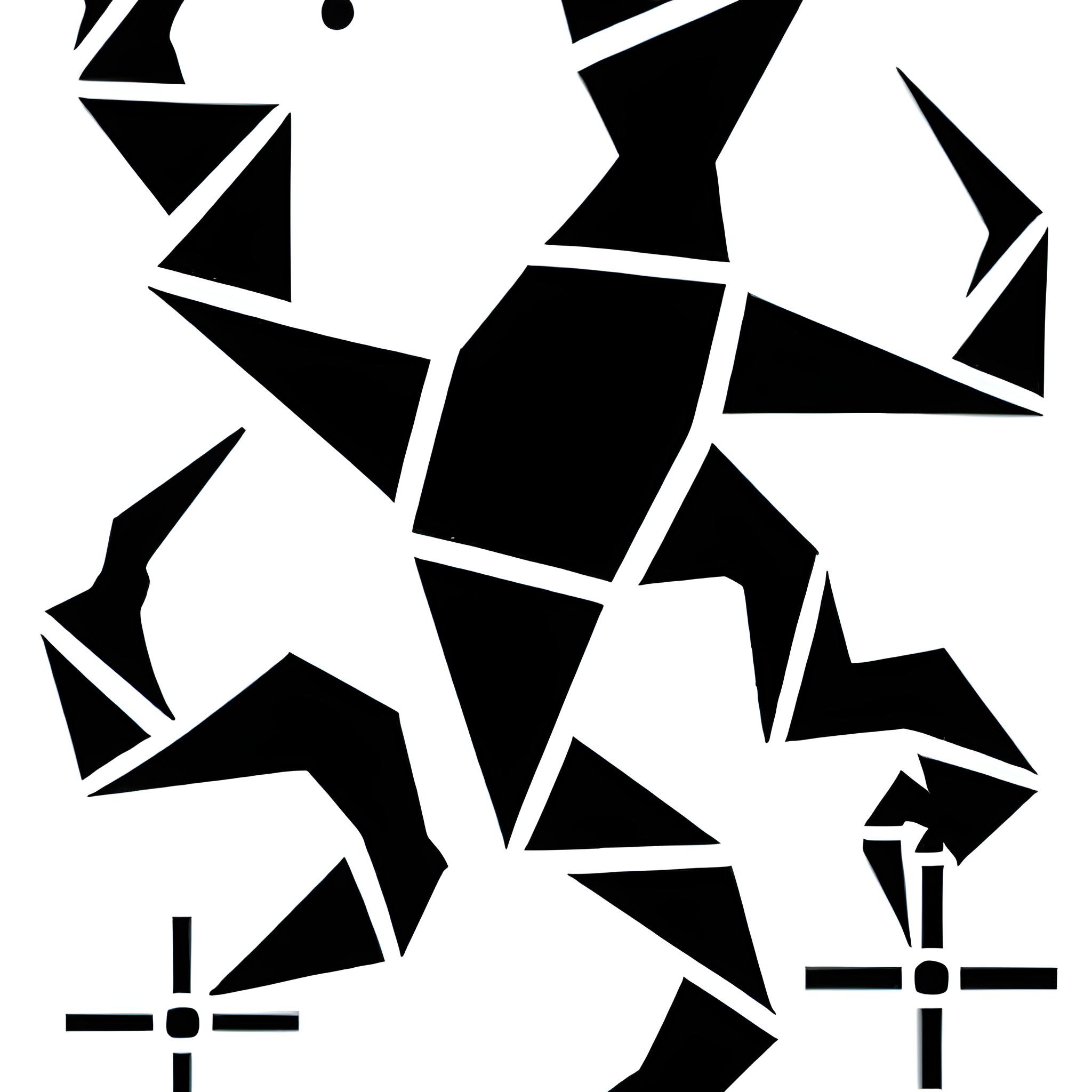
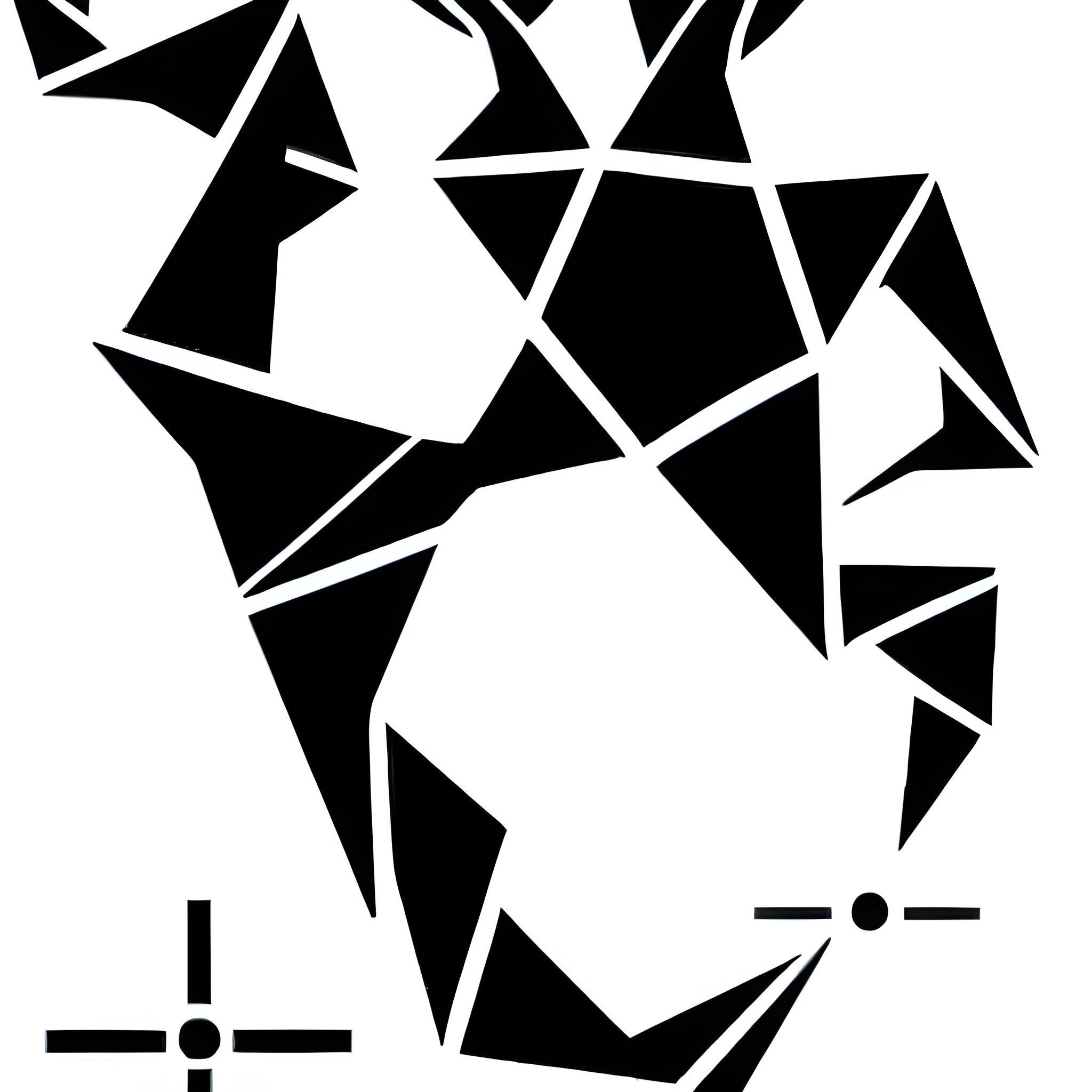












































































To begin, I made adjustments to the initial graphics, I did in the beginning, such as aligning them more parallel or concealing certain movements within the image. I generated 52 samples for the current model to ensure its accuracy and quality.



 Vector drawn training images
Vector drawn training imagesThe output generated by the AI was satisfactory, but it did not meet my expectations of perfection. In my eyes, there was still room for improvement. To further enhance the results, I realized that I needed to increase the sample size significantly. Instead of settling for a limited number of samples, I made the decision to generate a some more samples.
By increasing the sample count, I aimed to capture a broader range of variations and nuances within the generated images. This extensive dataset would provide a more comprehensive understanding of the AI's capabilities and allow me to select the most appealing and refined outcomes. I understood that investing the time and effort into creating a more samples would lead to a more refined and satisfactory end result, aligning closer with my artistic vision.






The parameters have always been prompt strength set to 20 and 30 samples. These are the iterations and feedback phases for the image noise. One of the most important players in this process is the DPM-Solver++: Fast Solver for Guided Sampling of Diffusion Probabilistic Models. It provides the closest result to my model, and it's the newest one available. The prompt options are always "Tom_peak style" for positive prompts and "photo" for negative prompts.
Image generation AI operates within a vast and realistic image domain, leveraging a wealth of learning material. Its primary objective is to simulate and fabricate human-like appearances or generate convincing representations of real-world objects. By analyzing and understanding existing visual data, such as photographs, the AI can generate highly realistic images that closely resemble genuine human creations or authentic scenes. This technology often incorporates stock material to enhance the diversity and realism of its output, seamlessly merging different visual elements from various sources.
The advancements in image generation AI have significant implications for numerous industries, including computer graphics, entertainment, advertising, and digital media. This technology enables the creation of visually compelling and immersive content, revolutionizing the way we interact with images. However, it's crucial to approach the use of this technology responsibly and consider the ethical concerns associated with its potential misuse. Fabricated images created by image generation AI can be employed to deceive or manipulate individuals, highlighting the need for responsible use and ethical considerations to ensure the positive impact of this technology on society.
Image generation AI faces challenges when it comes to generating abstract images due to the nature of abstraction itself. Abstract art often involves non-representational or non-realistic elements, focusing more on concepts, emotions, or non-literal interpretations. Unlike generating realistic or recognizable images, generating abstract images requires a departure from concrete visual references and a deeper understanding of artistic concepts.
One of the main difficulties lies in training the AI model on abstract art. Training data for image generation AI often consists of large datasets of photographs or real-world images, which are more concrete and easily discernible. Abstract art, on the other hand, is subjective and highly interpretive, making it challenging to curate a comprehensive dataset that captures the essence of abstract concepts.
Additionally, the evaluation of abstract images is subjective and depends on individual interpretation and artistic sensibility. This poses a challenge when training an AI model to generate abstract images that satisfy a diverse range of artistic preferences. It's difficult to define a specific set of rules or metrics to objectively assess the quality or success of generated abstract images, making it harder to train and optimize AI models for this particular task.
Despite these challenges, ongoing research and advancements in image generation AI techniques may help improve the generation of abstract images. Exploring alternative training strategies, incorporating more diverse and curated abstract art datasets, and refining evaluation methods can contribute to enhancing the AI's ability to generate compelling and aesthetically pleasing abstract images.